
الذكاء الاصطناعي في قياس التطبيقات بقى الكلمة اللي كل حد بيقولها بعد تحديثات iOS الخاصة بالتتبع. بعد ATT و SKAN، الأرقام في الداشبورد بقت ناقصة، مجمّعة، ومتأخرة 24 لـ 48 ساعة، وإنت بتاخد قرارات صرف بآلاف الدولارات عليها.
سمعت إنه بيحل المشكلة، بس مش عارف ده سحر تسويقي ولا حاجة تبني عليها فعلاً. المقال ده بيفصل بصدق بين اللي الـ AI بيعمله حقيقي وبين الوهم اللي ممكن يحرقلك ميزانية. هدخل في الموضوع على طول، من غير وعود فاضية.
خلاصة سريعة
- الذكاء الاصطناعي مش بيرجّع القياس الحتمي اللي اتغيّر بعد تحديثات iOS الخاصة بالتتبع. نظام iOS منع التتبّع الفردي، والـ AI مش بيلغي المنع ده. بيملا الفراغات بالاحتمال، فبيديك تقدير محترم مش حقيقة مؤكدة.
- أربع حاجات بيعملها فعلاً: يكمّل التحويلات الناقصة (modeled conversions)، يتوقّع قيمة العميل بدري (predictive LTV)، يقيس أثر الميزانية من فوق (MMM)، ويقيس الأثر الإضافي الحقيقي (incrementality). الأخيرة دي المعيار الذهبي.
- الرقم المتوقّع بيختلف عن مبيعاتك الحقيقية بـ 10 لـ 30%. ده تقدير إحصائي مش عدّ مباشر. تعامله كرقم مقاس 100% = فخ غالي.
- أرقام Meta و Google و TikTok المتوقّعة مجموعها أكبر من مبيعاتك الفعلية. كل منصة بتنسب الـ conversion لنفسها. محتاج طرف محايد يعاير الأرقام مقابل إيرادك الحقيقي.
- الـ AI صندوق أسود: جودة المخرجات = جودة المدخلات. لو الـ event mapping غلط، هيطلّعلك رقم واثق وغلط في نفس الوقت. للاتجاه والمقارنة تثق فيه، كرقم مطلق للـ CAC لأ إلا بعد معايرة.
قاموس سريع (ارجعله وقت ما تتوه)
- القياس الحتمي (deterministic): تعرف بالظبط مين عمل install من أي إعلان بدليل قاطع على مستوى الفرد. زي إيصال باسم الزبون. نظام iOS أوقف ده في معظم الحالات بعد تحديثات التتبع.
- القياس المتوقّع (modeled / probabilistic): تعيد بناء الصورة الناقصة بالاحتمال والإحصاء، مش بدليل. تقدير محترم، مش حقيقة.
- التحويلات المتوقّعة (modeled conversions): الـ conversions اللي الـ AI بيقدّرها لما البيانات المباشرة ناقصة بسبب SKAN و ATT، عشان يملا الفراغ.
- القيمة المتوقّعة (predictive LTV): توقّع قيمة العميل على المدى الطويل من سلوك أول يوم أو يومين، عشان تقرر صرف بسرعة من غير ما تستنى شهور.
- قياس مزيج الميزانية (MMM): تقيس أثر كل قناة على المبيعات من فوق (top-down)، من غير ما تنزل لمستوى الفرد. زي ما تبص على الميزانية كلها من برة بدل ما تتبّع كل زبون.
- الأثر الإضافي (incrementality): الأثر الحقيقي الزائد اللي جابه الإعلان فعلاً، يعني المبيعات اللي ما كانتش هتحصل لولا الإعلان. المعيار الذهبي.
هل الذكاء الاصطناعي يحل مشكلة قياس iOS فعلاً؟
الإجابة المباشرة: لأ، مش بيرجّع القياس الحتمي (deterministic) اللي اتغيّر بعد تحديثات iOS الخاصة بالتتبع. القياس الحتمي يعني تعرف بالظبط مين عمل install من أي إعلان بدليل قاطع على مستوى الفرد. نظام iOS منع التتبّع ده، والـ AI مش بيلغي المنع. اللي بيعمله إنه يملا الفراغات بالاحتمال (probabilistic)، يعني بيديك تقدير محترم مبني على الإحصاء، مش حقيقة مؤكدة على كل عميل.
خلّي الفرق واضح. نظام iOS غيّر القاعدة من أساسها: مفيش تتبّع فردي افتراضي بعد ATT. لو لسه مش واضح ليك إزاي ATT أوقفت القياس الفردي، ارجع لـ ما هو الـ ATT قبل ما تكمّل.
فيه فرق بين “بيحل” و”بيعوّض”. كلمة “يحل” معناها يرجّع لك اللي ضاع زي ما كان. ده مش بيحصل. كلمة “يعوّض” معناها يديك تقدير قريب من الحقيقة بدل الفراغ. ده اللي بيحصل فعلاً. لو دخلت على الموضوع متوقّع إنه هيرجّعلك دقة ما قبل ATT، هتاخد قرارات غلط. التوقّع الصح: تقدير أحسن من الفراغ، مش استرجاع للحقيقة.
إيه الفرق بين القياس الحتمي (deterministic) والقياس المتوقّع (modeled)؟
الإجابة المباشرة: الحتمي بيقولك بالظبط مين عمل install من أي إعلان بدليل قاطع على مستوى الفرد. المتوقّع (modeled) بيعيد بناء الصورة الناقصة بالاحتمال. الأول حقيقة، التاني تقدير إحصائي. ونظام iOS أوقف الأول في معظم الحالات بعد ATT.
التشبيه اللي يثبّت الفكرة: الـ AI زي محقق بيعيد بناء مشهد جريمة ناقصة منه لقطات الكاميرا. لو الأدلة اللي معاه نضيفة وكاملة، إعادة البناء بتطلع قريبة جداً من الحقيقة. لو الأدلة وسخة أو ناقصة، بيطلّعلك قصة مقنعة بس غلط. الفرق مش في ذكاء المحقق، الفرق في جودة الأدلة اللي دخلت له. ده بالظبط حال الـ modeling: نفس النموذج بيطلّعلك رقم صح أو غلط حسب نظافة المدخلات.
عشان كده الكلام عن “دقة الـ AI” من غير ما تبص على جودة المدخلات كلام ناقص. نظام SKAN نفسه بيديك إشارة مجمّعة ومتأخرة، والـ AI بيبني فوقها. لو مش فاهم الإشارة دي جاية منين، ارجع لـ SKAdNetwork بالعربي. الرسمة تحت بتوضّح إزاي بنتنقّل من إشارة iOS الناقصة لقرار تقدر تثق فيه.
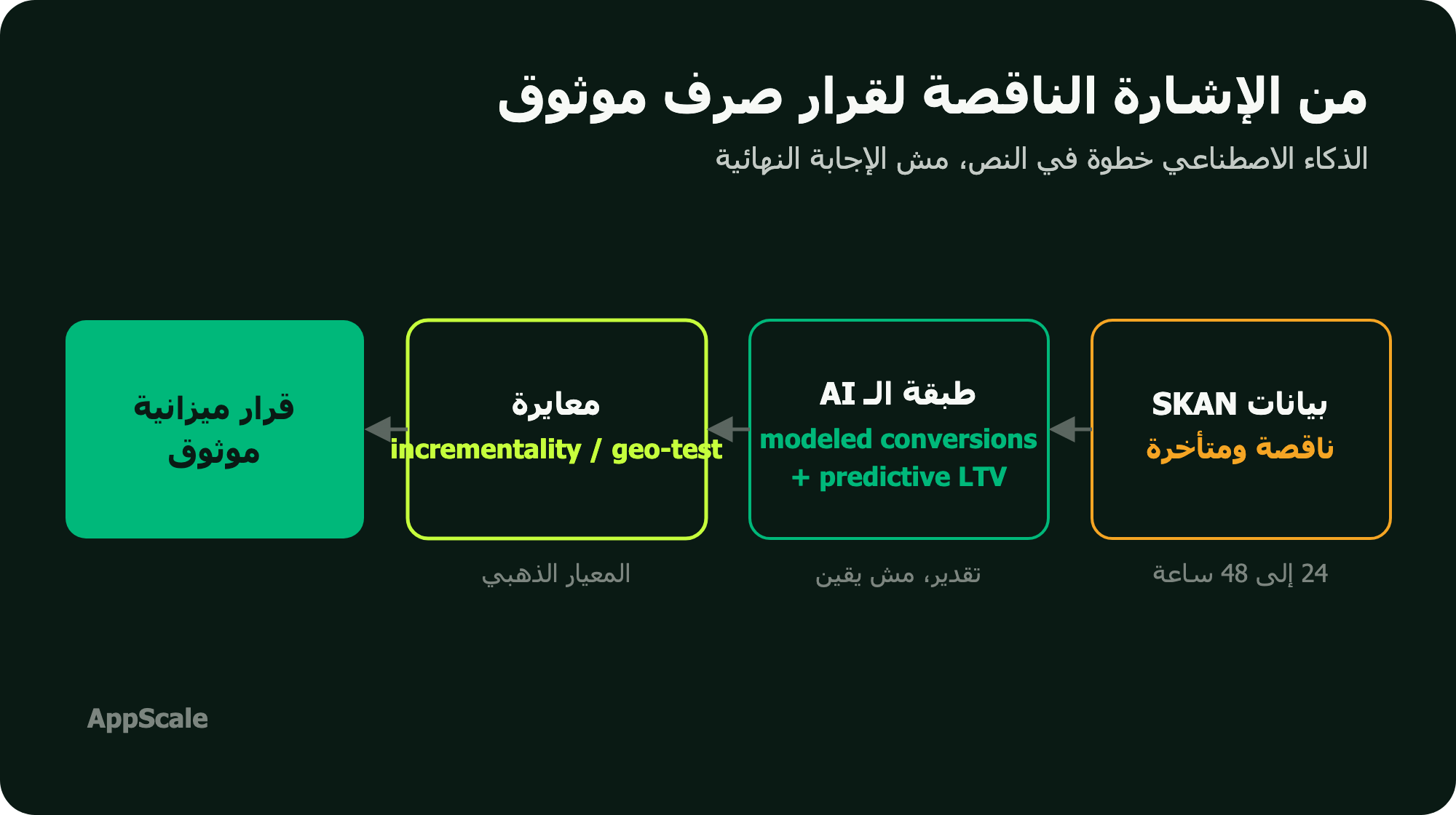
إيه اللي الـ AI بيعمله فعلاً في قياس التطبيقات؟ (الأربع حاجات)
الإجابة المباشرة: أربع حاجات حقيقية ومفيدة. التحويلات المتوقّعة (modeled conversions)، القيمة المتوقّعة (predictive LTV)، قياس مزيج الميزانية (MMM)، والأثر الإضافي (incrementality) اللي هو المعيار الذهبي. كل واحدة بتحل جزء مختلف من المشكلة.
- التحويلات المتوقّعة (modeled conversions): الـ AI بيقدّر الـ conversions الناقصة اللي ما قدرتش تشوفها بسبب SKAN و ATT. موجودة عشان تملا الفراغ في الصورة، مش عشان تستبدل العدّ المباشر.
- القيمة المتوقّعة (predictive LTV): بيتوقّع قيمة العميل على المدى الطويل من سلوكه في أول يوم أو يومين. موجودة عشان تقرر صرف بسرعة من غير ما تستنى شهور لحد ما القيمة الحقيقية تظهر.
- قياس مزيج الميزانية (MMM): بيقيس أثر كل قناة على مبيعاتك من فوق (top-down) بدل ما يتبّع كل عميل. موجودة عشان توزّع الميزانية الكلية بين القنوات، حتى من غير بيانات فردية.
- الأثر الإضافي (incrementality): بيقيس المبيعات الزيادة اللي جابها الإعلان فعلاً، يعني اللي ما كانتش هتحصل لولا الإعلان. ده المعيار الذهبي لأنه بيجاوب السؤال الحقيقي: الإعلان ده جاب لي فلوس زيادة ولا لأ.
التمييز اللي لازم تمسكه: ولا واحدة من الأربعة بتعرف “مين بالظبط عمل install من أي إعلان” على مستوى الفرد، زي ما ذكرت قبل كده. الأدوات دي بتشتغل على مستوى التقدير والاتجاه والمجموع، مش على مستوى العميل الواحد. الجدول تحت بيلخّص الأربعة وامتى تثق وامتى تحذر.
| الأداة | بتعمل إيه | امتى تثق فيها | امتى تحذر |
|---|---|---|---|
| التحويلات المتوقّعة (modeled conversions) | تملا الـ conversions الناقصة بعد SKAN | للاتجاه والمقارنة | تباين 10 لـ 30% عن الحقيقي |
| القيمة المتوقّعة (predictive LTV) | تتوقّع القيمة من أول يوم أو يومين | بعد معايرة بالأرقام الفعلية | إشارة مبكرة ضعيفة |
| قياس مزيج الميزانية (MMM) | تقيس أثر الميزانية من فوق (top-down) | لتوزيع الميزانية الكلي | مش بتدّي بيانات فردية |
| الأثر الإضافي (incrementality عبر geo أو holdout) | تقيس الأثر الإضافي الحقيقي | المعيار الذهبي للـ CAC الحقيقي | محتاج setup وصبر |
مش متأكد إن الـ event setup بتاعك بيدّي الـ AI بيانات نضيفة ولا ملوّثة؟
ده الفرق بين رقم تثق فيه ورقم بيكذب عليك. في 30 دقيقة نراجع الـ event setup والـ modeling ونوريك أنهي أرقامك تقدر تبني عليها قرار صرف فعلاً.
يعني إيه modeled conversions وليه بتختلف عن المبيعات الحقيقية؟
الإجابة المباشرة: التحويلات المتوقّعة (modeled conversions) هي الـ conversions اللي الـ AI بيقدّرها لما البيانات المباشرة ناقصة بسبب SKAN و ATT. طبيعي إنها تختلف عن مبيعاتك الحقيقية بـ 10 لـ 30%، لأنها تقدير إحصائي مش عدّ مباشر. الخطر الحقيقي إنك تعاملها كرقم مقاس بدقة 100%.
منين بتيجي الفجوة دي؟ من إن الـ AI بيشوف جزء بس من الصورة (اللي ATT سمح بيه) وبيقدّر الباقي بالاحتمال. التقدير ده محترم، بس بطبيعته فيه هامش خطأ. مفيش نموذج بيطلّع الرقم الحقيقي بالضبط لما نص الإشارة محجوبة.
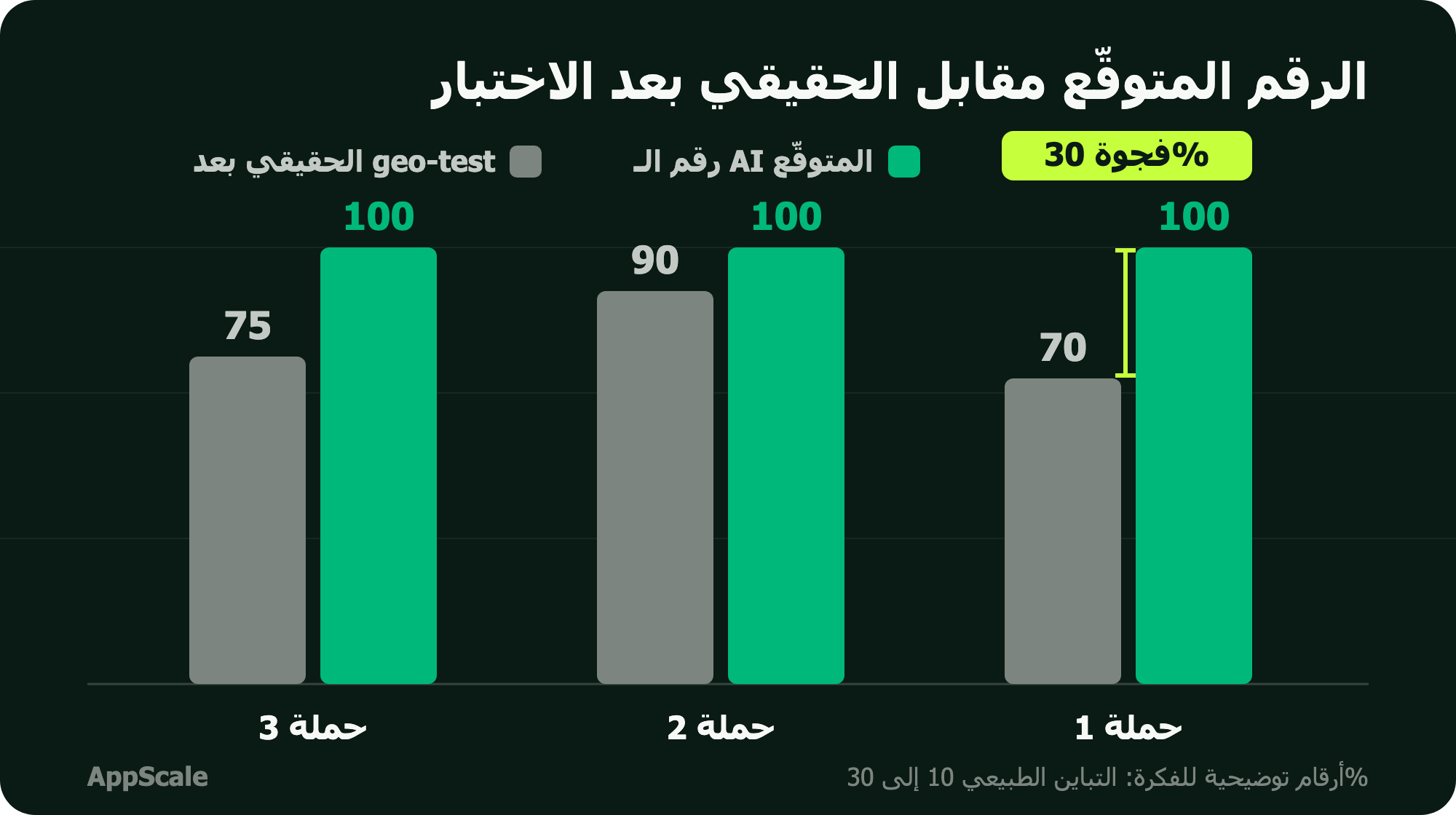
هنا الفخ الغالي بسيناريو بيتكرر كتير. تخيّل مشغّل شاف الـ ROAS على الأرقام المتوقّعة عالي، فزوّد الصرف 40% بناءً عليه. بعدين عمل geo-test (تجربة بيطفّي فيها الإعلان في منطقة جغرافية ويقارنها بمنطقة الإعلان فيها شغّال، عشان يشوف الفرق الحقيقي). لو الـ geo-test طلّع الأثر الإضافي (الـ lift) نص الرقم المتوقّع بس، يبقى الـ 40% زيادة كانت مبنية على رقم متضخّم، وجزء كبير من الميزانية الزيادة راح على هوا.
القاعدة العملية: استخدم الـ modeled conversions للاتجاه أيوة (الحملة دي أحسن من دي، الاتجاه طالع لفوق)، كرقم مطلق تبني عليه قرار صرف كبير لأ. الرسم تحت بيوضّح الفجوة بين الرقم المتوقّع والرقم الحقيقي.
يعني إيه predictive LTV وامتى أثق فيه؟
الإجابة المباشرة: القيمة المتوقّعة (predictive LTV) هي توقّع الـ AI لقيمة العميل على المدى الطويل، مبني على سلوكه في أول يوم أو يومين، عشان تقرر صرف بسرعة من غير ما تستنى شهور. تثق فيه للمقارنة النسبية والاتجاه. كرقم مطلق ما تثقش فيه إلا بعد معايرة بالأرقام الفعلية.
ليه ده مهم؟ لأن قيمة العميل الحقيقية بتظهر بعد شهور، وإنت محتاج تقرر دلوقتي تزوّد صرف على أنهي حملة. القيمة المتوقّعة بتديك إشارة بدري بدل ما تنتظر. القرار السريع ده ميزة حقيقية في سوق المنافسة فيه قوية.
بس فيه شرط للثقة. كلمة “معايرة” (calibration) معناها إنك تقارن توقّعات النموذج بالأرقام الحقيقية اللي ظهرت بعد فترة، وتعدّل النموذج لحد ما يقرّب منها. زي ساعة بتظبطها على التوقيت الصح كل فترة. من غير معايرة، الـ predictive LTV رقم معلّق في الهوا.
الخطر الأساسي: الإشارة المبكرة الضعيفة. سلوك يوم واحد أو يومين أحياناً مش كفاية عشان النموذج يفرّق بين عميل هيدفع كتير وعميل هيمشي. لو بنيت قرار كبير على إشارة مبكرة ضعيفة، بتاخد مخاطرة. عشان كده الـ predictive LTV بيكمّل حساب الـ CAC، مش بيستبدله. لو محتاج تفهم إزاي تحسب التكلفة الحقيقية اللي بتقارنها بالقيمة دي، ارجع لـ الـ CAC الحقيقي.
ليه أرقام المنصات المتوقّعة بتطلع أكبر من مبيعاتي الحقيقية؟
الإجابة المباشرة: كل منصة (Meta، Google، TikTok) بتنسب الـ conversion لنفسها بنموذجها الخاص. فلو جمعت الأرقام المتوقّعة من الكل، المجموع بيطلع أكبر من مبيعاتك الحقيقية. ده تضارب نماذج مش كذب مقصود. عشان تعرف الحقيقة، محتاج طرف محايد يعاير الأرقام مقابل إيرادك الفعلي.
الظاهرة دي اسمها over-attribution (المبالغة في النسب). معناها إن كذا منصة بتنسب نفس الـ conversion لنفسها. العميل ممكن يكون شاف إعلان على Meta وإعلان على TikTok قبل ما يشتري، فالاتنين بيدّعوا الفضل. النتيجة إن مجموع الـ conversions بتاعتهم أكبر من عدد عملياتك الحقيقية.
وفيه نقطة أهم: المنصة متضاربة المصلحة. شركة Meta بتقيس أداء إعلانات Meta وبتديك الرقم. لما الطرف اللي بيقيس هو نفسه الطرف اللي بيبيعلك الإعلان، الرقم بيميل لصالحه بطبيعته. مش بالضرورة كذب، بس مش حيادي.
الحل: طرف محايد بيعاير كل الأرقام مقابل إيرادك الحقيقي اللي في حسابك البنكي. ده دور الـ MMP (الأداة اللي بتجمّع كل مصادرك وتنسب الـ conversions من مكان محايد). لو لسه مش واضح ليك دور الأداة دي، ارجع لـ ما هو الـ MMP. القاعدة: ما تجمعش أرقام المنصات وتعاملها كحقيقة. عايرها بإيرادك الفعلي الأول.
امتى أثق في رقم الـ AI وامتى لأ قبل ما أزوّد صرف؟
الإجابة المباشرة: للاتجاه والقرار النسبي (أنهي حملة أحسن، الاتجاه رايح فين) أيوة، تثق. كرقم مطلق للـ CAC الحقيقي لأ، إلا بعد معايرة بالأثر الإضافي (incrementality) عبر geo-test أو holdout. الـ AI صندوق أسود، وجودة المخرجات = جودة المدخلات. لو الـ event mapping غلط، هيطلّعلك رقم واثق وغلط في نفس الوقت.
كلمة “صندوق أسود” (black-box) معناها إنك بتشوف الرقم اللي طالع، بس مش شايف إزاي النموذج وصل له بالظبط. ده مش عيب في حد ذاته، بس معناه إنك ما تقدرش تثق في المخرجات إلا لو واثق في المدخلات. والـ holdout يعني إنك تمنع الإعلان عن مجموعة من المستخدمين متعمّد، وتقارن سلوكهم بمجموعة شافت الإعلان، عشان تقيس الفرق الحقيقي اللي جابه الإعلان.
قبل ما تزوّد صرف بناءً على أرقام الـ AI، عدّي على الـ checklist ده:
- الـ event setup متحقّق منه؟ الأحداث اللي بتقيسها مربوطة بالفلوس فعلاً، مش بأحداث رخيصة زي “فتح التطبيق”. الـ event mapping غلط = رقم واثق وغلط.
- الرقم متطابق مع إيرادك الفعلي؟ قارن مجموع الـ conversions المتوقّعة بإيرادك الحقيقي في حسابك. لو الفجوة أكبر من 30%، فيه حاجة محتاجة مراجعة.
- عملت geo-test أو holdout؟ من غير قياس الأثر الإضافي، إنت بتثق في رقم متوقّع من غير ما تتأكد إنه حقيقي. ده الشرط للرقم المطلق.
- بتقارن نفس النموذج عبر الوقت؟ لو النموذج اتغيّر بين الشهر ده واللي فات، المقارنة مش عادلة. ثبّت النموذج عشان الاتجاه يبقى ليه معنى.
دي نفس عائلة الأخطاء اللي بتخلّي القياس يكذب عليك. لو عايز تشوف العلامات اللي بتدلّك إن الـ setup بتاعك بيضلّلك، ارجع لـ أخطاء الـ tracking setup.
اقرأ كمان
- ما هو الـ ATT: إزاي خصوصية Apple غيّرت قياس إعلاناتك على iOS
- SKAdNetwork بالعربي: إزاي iOS غيّر قياس التطبيقات
- إزاي تحسب الـ CAC الحقيقي لتطبيقك (الرقم اللي بتشوفه أقل من الحقيقة)
- 7 علامات إن الـ tracking setup بتاعك بيكذب عليك (وبتخسر فلوس)
الـ AI هيديك أرقام واثقة بغض النظر عن جودة مدخلاتها
السؤال الوحيد: مدخلاتك نضيفة ولا ملوّثة؟ في 30 دقيقة نراجع الـ event setup والـ modeling ونوريك أنهي أرقام تقدر تبني عليها قرار صرف فعلاً. جلسة استشارية بـ $50: تشخيص من غير التزام.
أسئلة شائعة
هل الذكاء الاصطناعي يرجّع القياس الحتمي اللي اتغيّر بعد تحديثات iOS الخاصة بالتتبع؟
لأ. الـ AI بيديك تقدير احتمالي يملا الفراغ، مش استرجاع للقياس الحتمي اللي كان على مستوى الفرد. نظام iOS منع التتبّع الفردي، والـ AI بيشتغل جوه المنع ده مش بيلغيه. التوقّع الصح: تقدير أحسن من الفراغ، مش دقة ما قبل ATT.
إيه الفرق بين modeled conversions والمبيعات الحقيقية؟
الـ modeled conversions تقدير إحصائي بيملا الـ conversions الناقصة بعد SKAN و ATT. بيختلف عن المبيعات الحقيقية بـ 10 لـ 30% لأنه تقدير مش عدّ مباشر. تستخدمه للاتجاه والمقارنة، مش كرقم مطلق تبني عليه قرار صرف كبير لوحده.
هل أقدر أبني قرار صرف على الرقم المتوقّع لوحده؟
للاتجاه والمقارنة النسبية أيوة (أنهي حملة أحسن). كرقم مطلق للـ CAC الحقيقي لأ، إلا بعد معايرة بالأثر الإضافي (incrementality) عبر geo-test أو holdout. من غير المعايرة دي، ممكن تزوّد صرف على رقم متضخّم.
ليه أرقام Meta و Google المتوقّعة أكبر من مبيعاتي الفعلية؟
لأن كل منصة بتنسب الـ conversion لنفسها بنموذجها، فالعميل الواحد ممكن ينحسب أكتر من مرة (over-attribution). والمنصة متضاربة المصلحة لأنها بتقيس إعلانها بنفسها. محتاج طرف محايد زي الـ MMP يعاير الأرقام مقابل إيرادك الفعلي.
يعني إيه predictive LTV وامتى أثق فيه؟
هو توقّع قيمة العميل على المدى الطويل من سلوك أول يوم أو يومين، عشان تقرر صرف بسرعة. تثق فيه للمقارنة النسبية بين الحملات، وكرقم مطلق بعد معايرته بالأرقام الفعلية. الخطر إنك تبني قرار كبير على إشارة مبكرة ضعيفة.
يعني إيه إن الـ AI صندوق أسود في القياس؟
معناه إنك بتشوف الرقم الطالع بس مش شايف إزاي النموذج وصل له. النتيجة: جودة المخرجات = جودة المدخلات. لو الـ event mapping غلط، النموذج هيطلّعلك رقم واثق وغلط في نفس الوقت. عشان كده ما تثقش في المخرجات إلا لو واثق في المدخلات.
إيه الـ checklist قبل ما أزوّد صرف بناءً على أرقام الـ AI؟
أربع نقاط: الـ event setup متحقّق منه ومربوط بالفلوس، الرقم متطابق مع إيرادك الفعلي، عملت geo-test أو holdout لقياس الأثر الإضافي، وبتقارن نفس النموذج عبر الوقت. لو نقطة ناقصة، إنت بتزوّد صرف على رقم مش متأكد منه.